|
Hello! I am a fifth-year PhD student in Electrical Engineering at Stanford University. I have the privilege to work with Professor James Zou in the Biomedical Data Science department and Professor Daniel E. Ho in the Law School. I am funded by the Stanford Bio-X SIGF Fellowship. Previously, I helped develop AI for cancer detection at DeepHealth (acquired by RadNet) in Cambridge, MA and worked on spam detection at Google. I was also at Harvard University for a Master's degree in computational science and at Duke University for my undergraduate studies.
Email / Google Scholar / Twitter / Github |

|
|
I broadly research at the intersection of health and artificial intelligence. I'm interested in answering questions relating to AI regulation in medicine, machine learning for cancer diagnostics, and computational pathology.
|
LLMs |
|
|
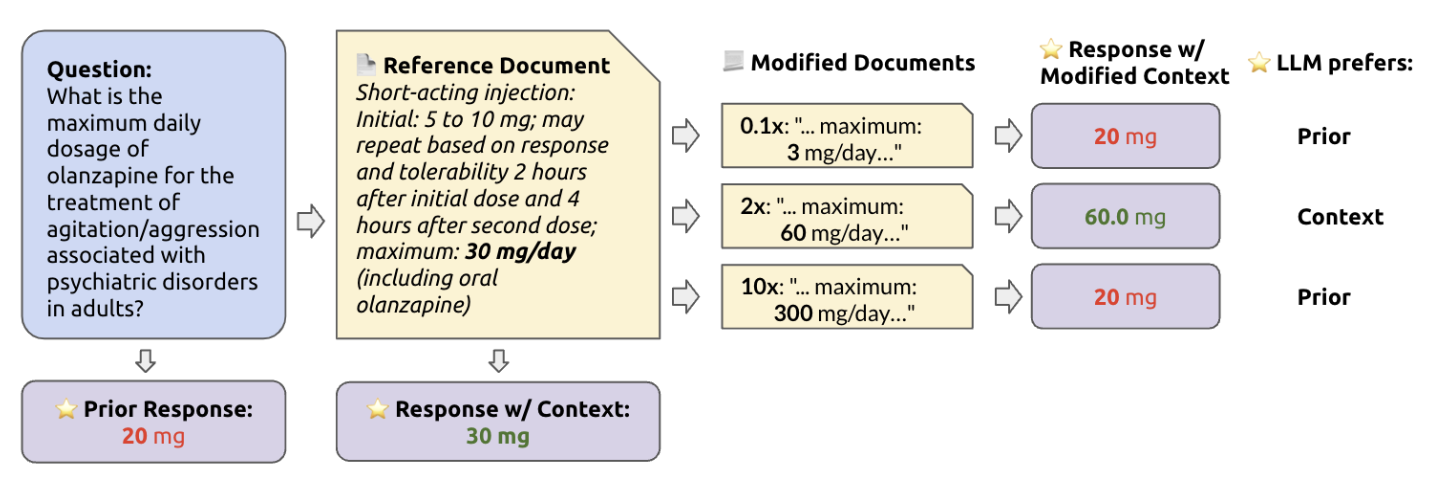
Kevin Wu*, Eric Wu*, James Zou NeurIPS, Datasets and Benchmarks Track, 2024 Retrieval augmented generation (RAG) helps LLMs with updated knowledge, but also risks presenting incorrect or harmful content. This study benchmarks six LLMs, including GPT-4, on their ability to handle conflicting information, revealing that LLMs often override correct knowledge with retrieved errors, especially when they are unsure of their initial response. |
|
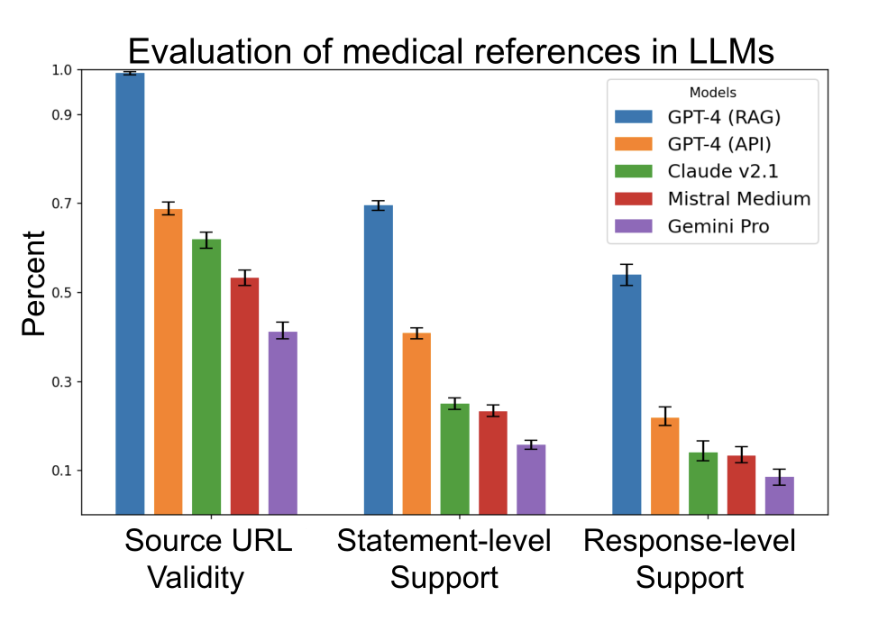
Kevin Wu*, Eric Wu*, Ally Cassasola, Angela Zhang, Kevin Wei, Teresa Nguyen, Sith Riantawan, Patricia Shi Riantawan, Daniel E Ho, James Zou In submission, 2024 Large language models (LLMs) are increasingly used to answer medical questions. We evaluate their ability to cite relevant sources, finding that many generated sources do not fully support the claims made. We introduce SourceCheckup, a pipeline for evaluating citation relevance, and provide an open-source dataset for future research. |
|
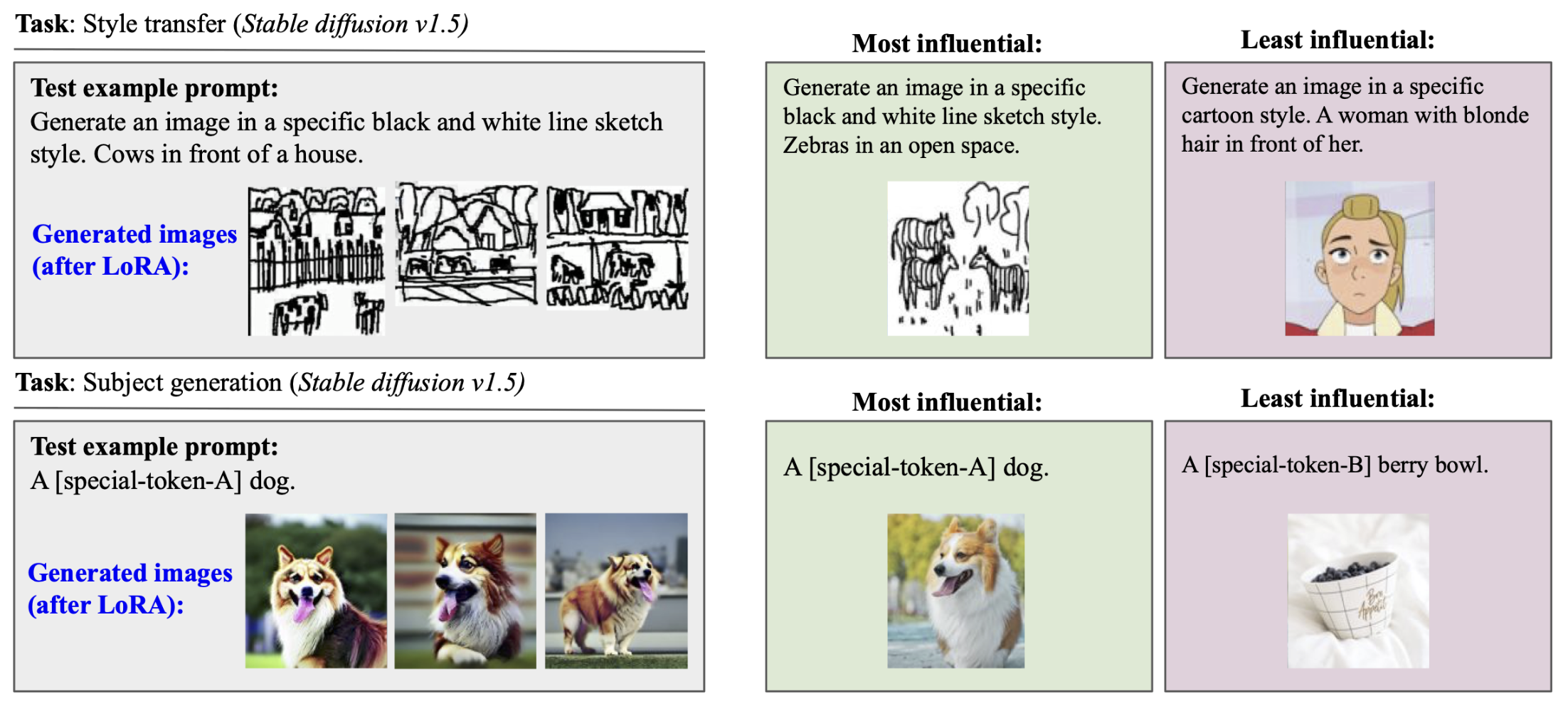
Yongchan Kwon*, Eric Wu*, Kevin Wu*, James Zou ICLR, 2023 DataInf is an efficient influence approximation method that is practical for large-scale generative AI models. Leveraging an easy-to-compute closed-form expression, DataInf outperforms existing influence computation algorithms in terms of computational and memory efficiency. Our theoretical analysis shows that DataInf is particularly well-suited for parameter-efficient fine-tuning techniques such as LoRA. |

|
Weixin Liang*, Mert Yuksekgonul*, Yining Mao*, Eric Wu*, James Zou Patterns, 2023 We found that GPT detectors often misclassify non-native English writing as AI-generated, highlighting the need to address these biases to ensure fairness and avoid marginalizing non-native speakers in evaluative settings. |
Pathology |
|
|
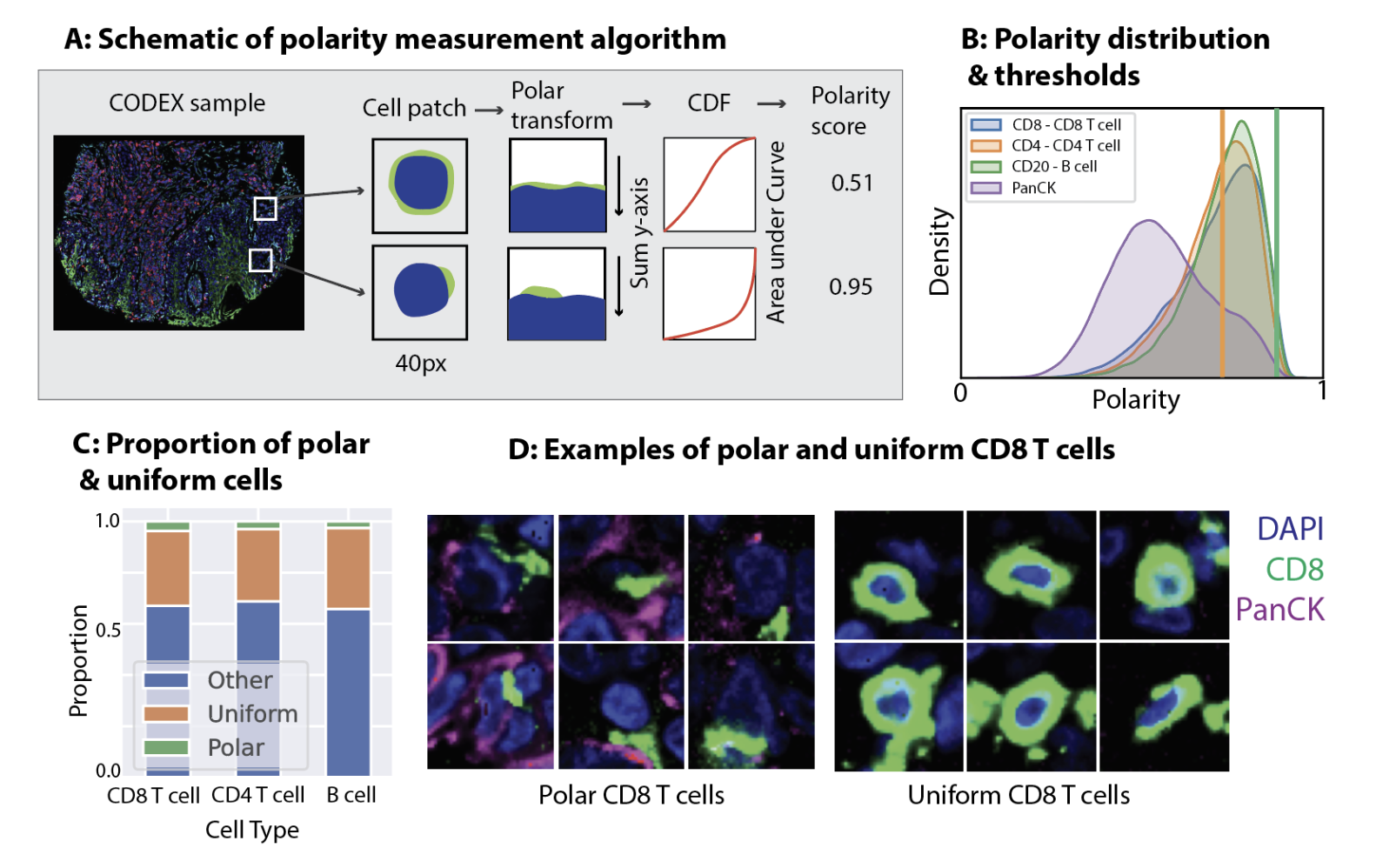
Eric Wu, Zhenqin Wu, Aaron T Mayer, Alexandro E Trevino, James Zou Pacific Symposium on Biocomputing, 2023 We develop a metric to define surface protein polarity from immunofluorescence imaging data, applying it to identify immune cell states within tumor microenvironments and improve deep learning models for predicting patient outcomes. |

|
Eric Wu*, Alexandro E. Trevino*, Zhenqin Wu, Kyle Swanson, [...], Aaron T. Mayer, James Zou PNAS Nexus, 2022 7-UP is a machine learning framework that can computationally generate in silico 40-plex CODEX at single-cell resolution from a standard 7-plex mIF panel by leveraging cellular morphology. |
Clinical AI |
|
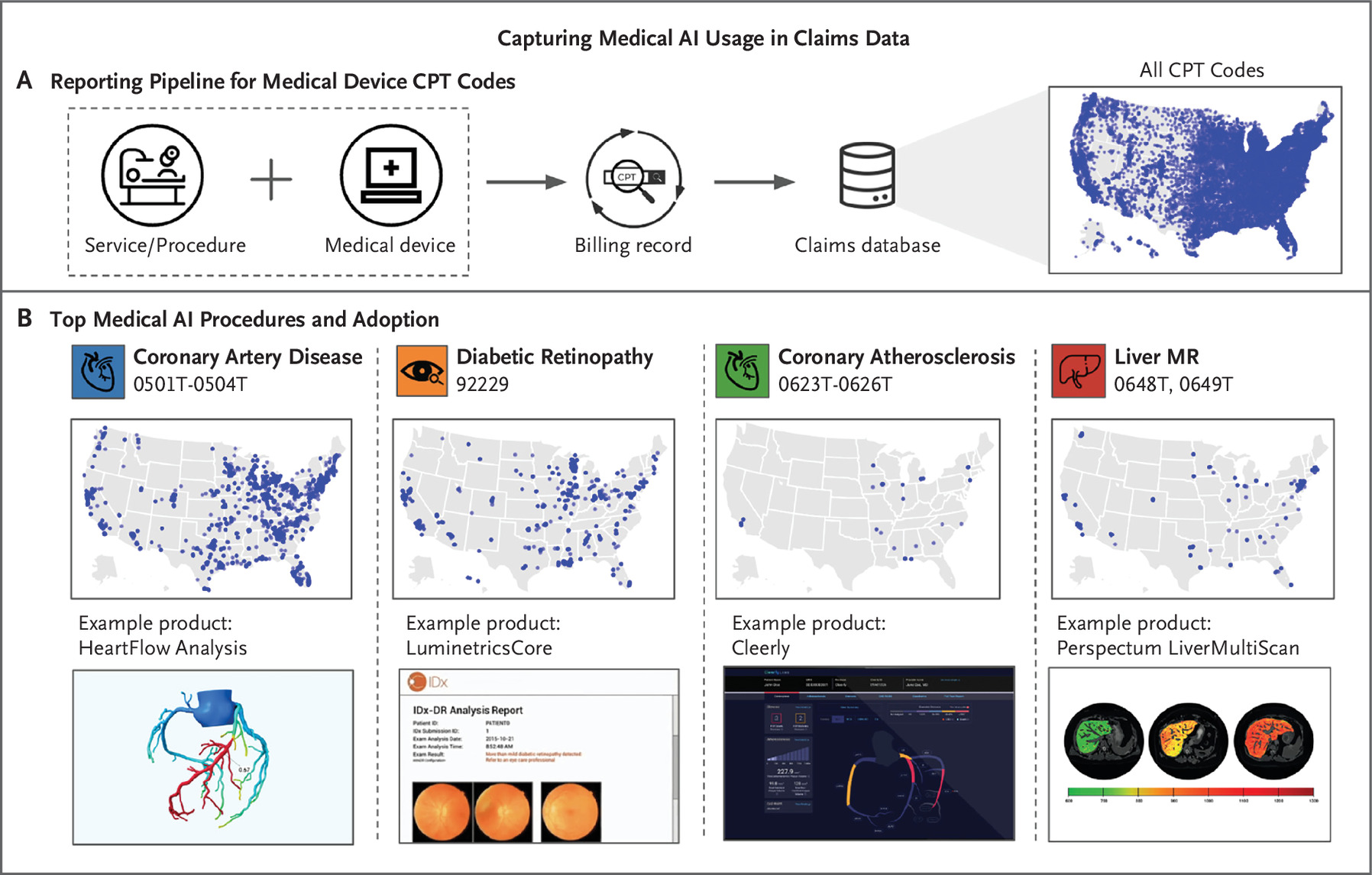
|
Kevin Wu*, Eric Wu*, Brandon Theodorou, Weixin Liang, Christina Mack, Lucas Glass, Jimeng Sun, James Zou NEJM AI, 2023 We systematically quantify the adoption and usage of medical AI devices in the United States by analyzing a comprehensive nationwide claims database of 11 billion CPT claims. We find that despite hundreds of AI devices being approved by the FDA, only a handful are used clinically as reported in insurance claims data. |
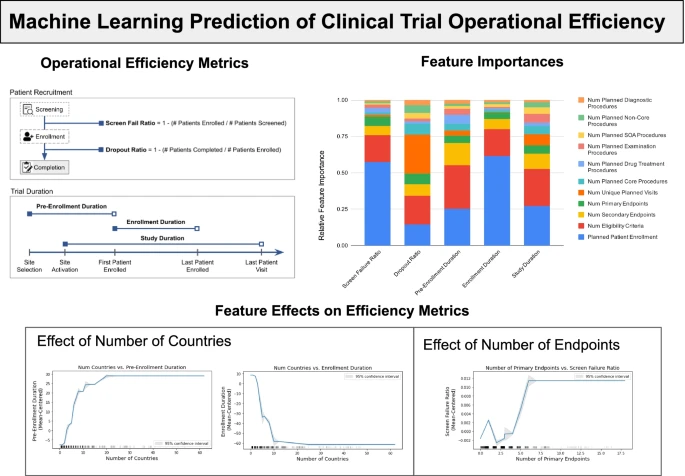
|
Kevin Wu*, Eric Wu*, Michael DAndrea, Nandini Chitale, Melody Lim, Marek Dabrowski, Klaudia Kantor, Hanoor Rangi, Ruishan Liu, Marius Garmhausen, Navdeep Pal, Chris Harbron, Shemra Rizzo, Ryan Copping, James Zou The AAPS Journal, 2022 We developed a machine learning model to predict clinical trial operational efficiency using a novel dataset from Roche, encompassing over 2,000 clinical trials across multiple disease areas. |

|
Eric Wu, Kevin Wu, Roxana Daneshjou, David Ouyang, Daniel E. Ho, James Zou Nature Medicine, 2021 A comprehensive overview of medical AI devices approved by the US Food and Drug Administration sheds new light on limitations of the evaluation process that can mask vulnerabilities of devices when they are deployed on patients. |
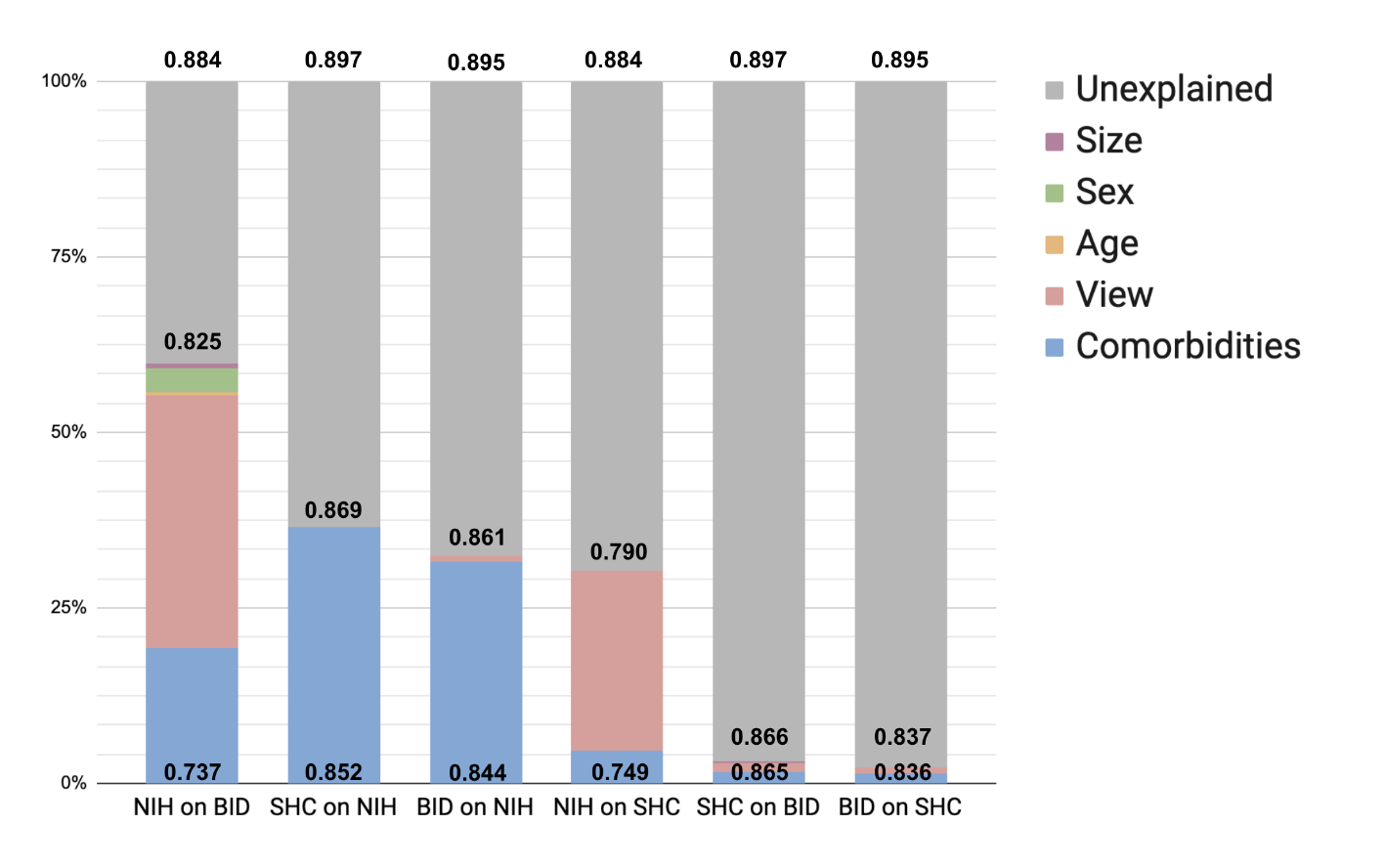
|
Eric Wu*, Kevin Wu*, James Zou NeurIPS, Machine Learning for Health Workshop, 2021 We provide a framework to quantify the impact of biases on AI performance disparities across different sites, demonstrating its utility in explaining significant discrepancies in model performance, as shown in a case study of pneumothorax detection. |
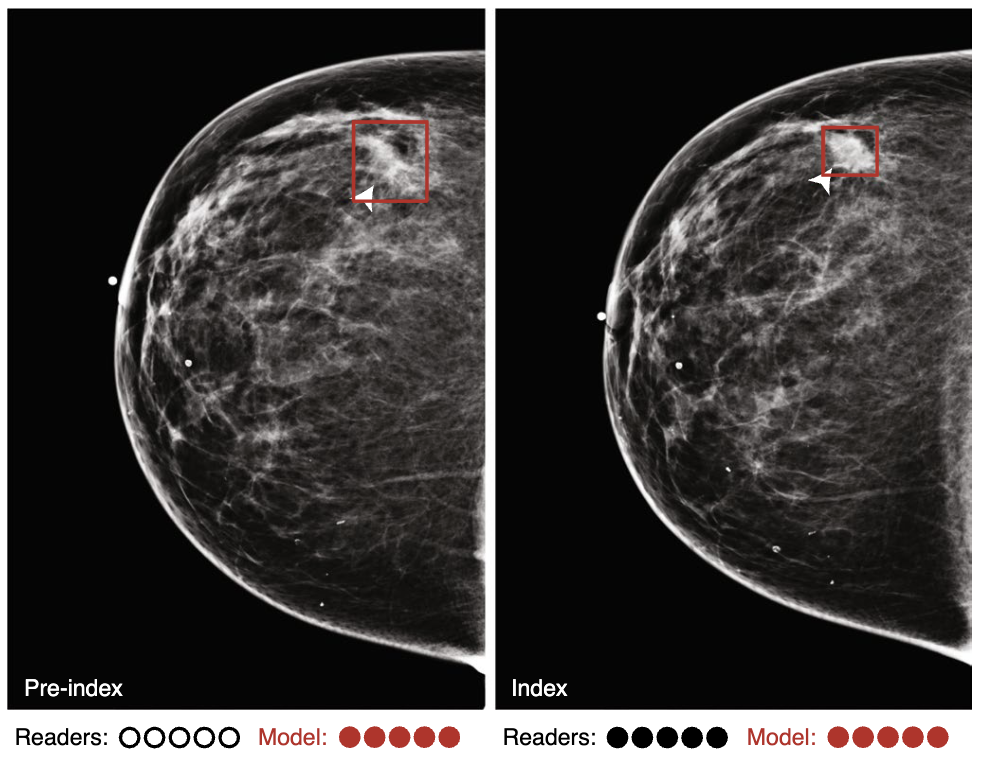
|
William Lotter, Abdul Rahman Diab, Bryan Haslam, Jiye G Kim, Giorgia Grisot, Eric Wu, Kevin Wu, Jorge Onieva Onieva, Yun Boyer, Jerrold L Boxerman, Meiyun Wang, Mack Bandler, Gopal R Vijayaraghavan, A Gregory Sorensen Nature Medicine, 2021 We present an annotation-efficient deep learning approach that achieves state-of-the-art performance in breast cancer detection, addressing challenges such as obtaining large annotated datasets and ensuring generalization across diverse populations and imaging modalities. |
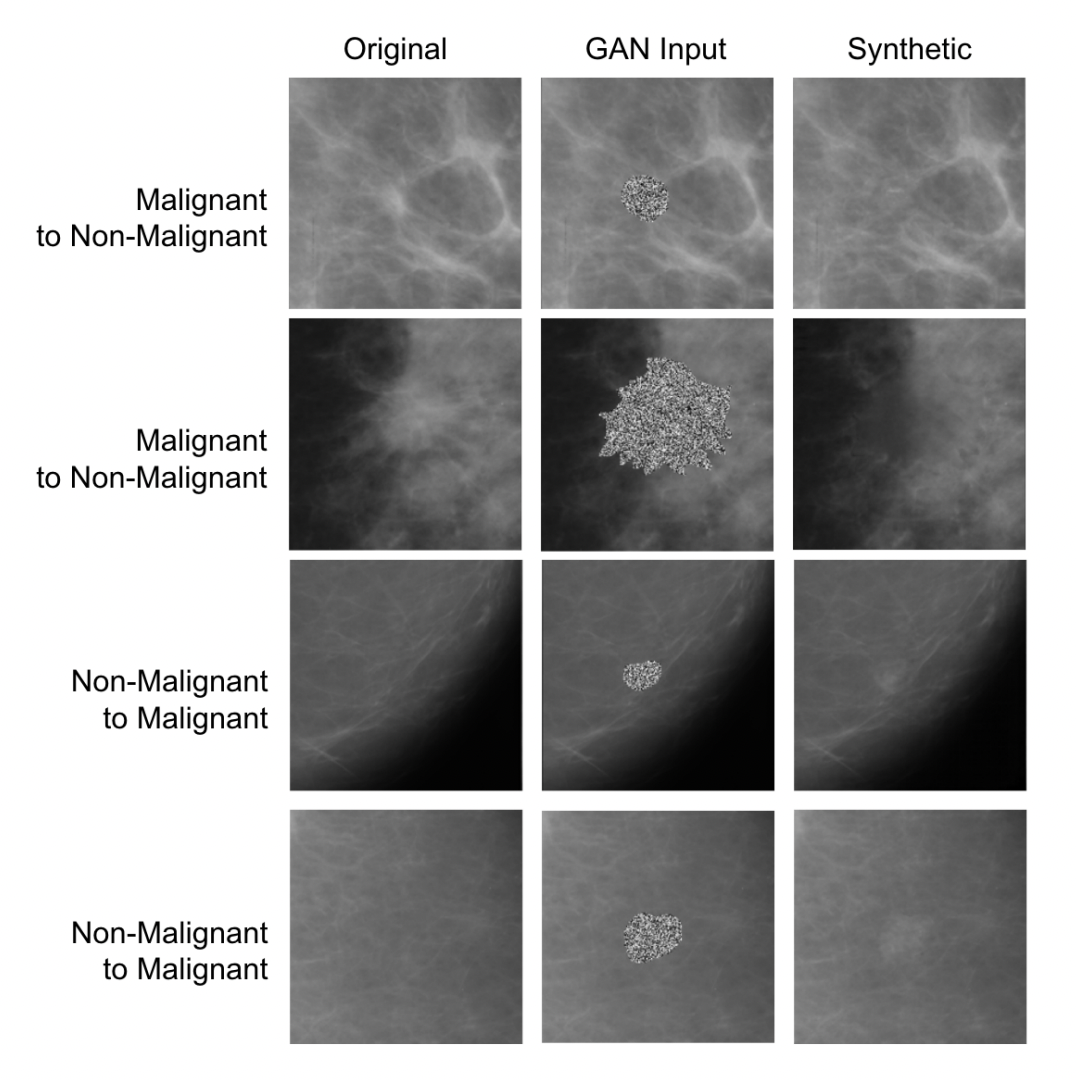
|
Eric Wu*, Kevin Wu*, David Cox, William Lotter MICCAI, Breast Image Analysis Workshop, 2018 We use generative adversarial networks (GANs) to synthesize mammogram image patches for producing synthetic training data toward breast cancer detection. |
Reviews |
|
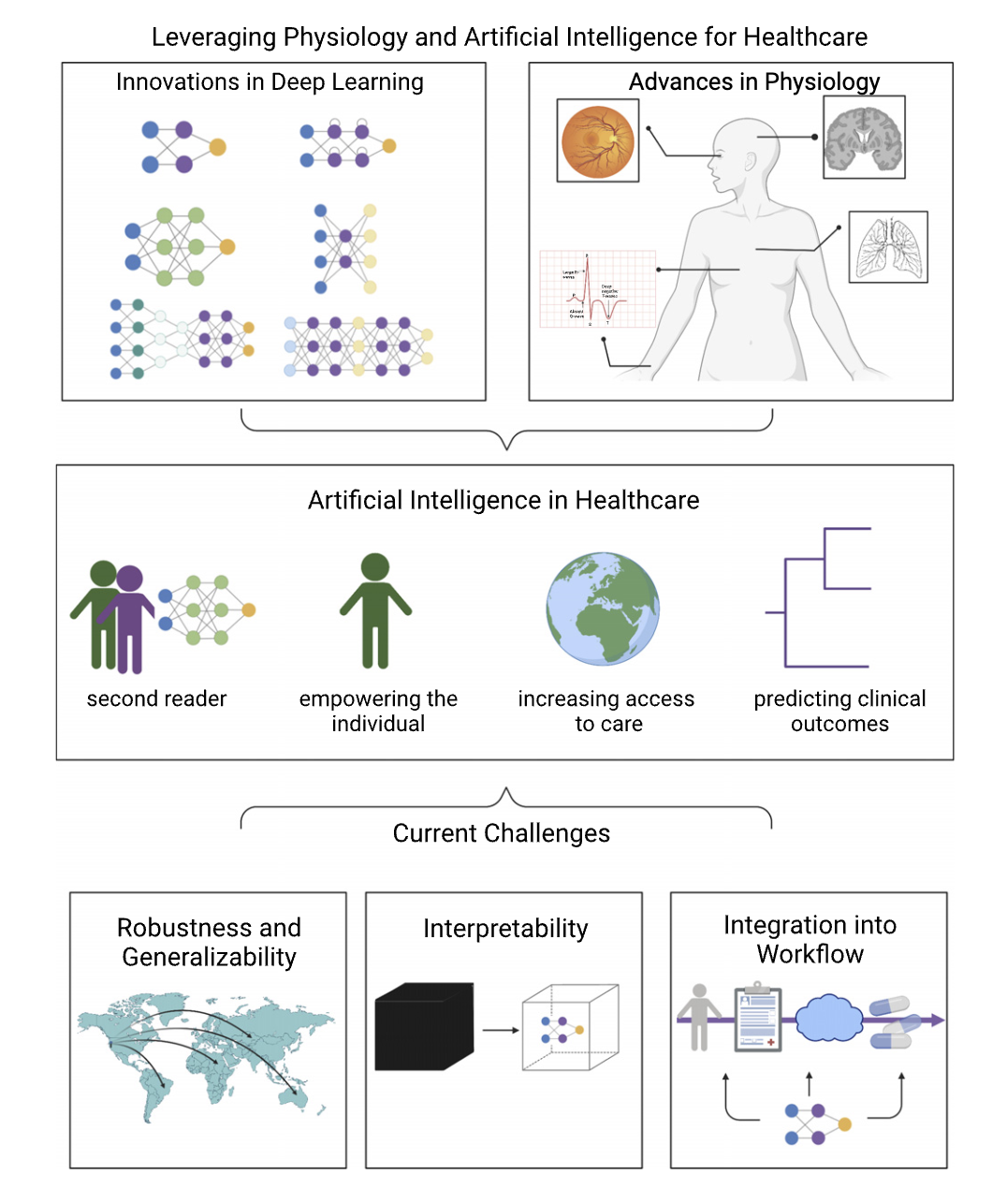
|
Angela Zhang, Zhenqin Wu, Eric Wu, Matthew Wu, Michael P. Snyder, James Zou, Joseph C. Wu Physiological Reviews, 2023 Artificial intelligence in health care has experienced remarkable innovation and progress in the last decade. In this review, we explore how AI has been used to transform physiology data to advance health care, focusing on automating tasks, increasing access, and augmenting capabilities. |
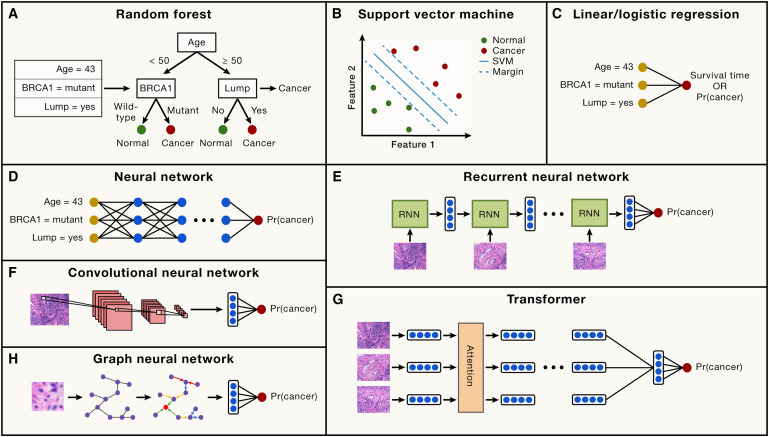
|
Kyle Swanson*, Eric Wu*, Angela Zhang*, Ash A Alizadeh, James Zou Cell, 2023 We review recent applications of machine learning in clinical oncology, focusing on its use in diagnosing cancers, predicting patient outcomes, and informing treatment planning, particularly through medical imaging and molecular data analysis. |
|
|

|
Eric Wu, Kevin Wu Teaching a four-week course on the fundamentals of deep learning! We've partnered with our friends at UpLimit, an online teaching platform. |
|
Template adapted from this repo. |